


The wild and magical world of claims
All aboard healthcare's financial data train 🚂🚂🚂


In the year 1996, Quad City DJs released their hip-hop anthem “C'Mon n' Ride It (The Train)”. As different musical artists across the US have started to get involved in healthcare unexpectedly, we at Flexpa called them up1 to lay down a new track for us on the latest and greatest train: claims data.
Come on, access the claims, hey, unlock it
Come on, access the claims, hey, unlock it
Come on, access the claims, hey, unlock it
Come on, access the claims, hey, unlock it
Ah, ah, ah, ah, ah
I know I can code, I know I can code, I know I can code, I know I can code
Ah, ah, ah, ah, ah
I know I can code, I know I can code, I know I can code, I know I can code
Deep in healthcare, where we hold this role
It's those Data Teams and you, we aim for patient control
So if you wanna sift through medical claims
Just log on to the EHR frame
We're gonna filter, ooh, HIPAA-compliant go, folks
So get your clinicians, and your data scientists too
Queue it up now
Click, click, dive into this, click, click
Hey, no need to hesitate, let's improve patient care
I aim to bring you insights, to diagnose with flair
If you're cautious on privacy, let's make it worthy
Don't be skeptical, until you've analyzed it
So to all healthcare orgs, know I'm mentioning your game
The atomic unit of healthcare financials in America, the claim, is a much maligned and somewhat mediocre instrument for its core purpose (facilitating payment to a provider by an insurer for services rendered). It’s unfortunately coupled by law (not regulation) to an outdated and archaic standard, X12, that purposefully buries their documentation behind paywalls. Does it work? Most of the time. Do we deserve better? Absolutely.
However, beyond that primary application for transactional exchange, the claim is actually a fantastic tool for understanding a patient’s health. Claims document all the touchpoints a patient has had with the healthcare system and include the core data of care that occurred - diagnoses, medications, procedures, and care team. In contrast to provider-sourced clinical information, they also show the financial layer, which can be crucial for various analytical tasks—be it cost optimization, compliance checks, or risk assessment. Perhaps most importantly, claims are also highly standardized relative to almost all other healthcare data sources, due to the congressionally mandated use of X12 and associated code systems.
When it comes to health data, whether provider, payer, or wearable, there are three fundamental barriers when it comes to really understanding a patient’s health:
Fragmentation: Care occurs in many places, and those places are siloed. Building the trust and confidence between competitors at a regional or national scale to pool in a centralized fashion or share in a networked fashion is a challenging proposition.
Access: Health data is sensitive. Therefore, the laws and regulations around health data are restrictive in who can view health data (based on role or purpose of use). Even if fragmentation is solved, not every role that wants to help a patient has the privilege of doing so.
Completeness: Compared to data from other industries, health data is wildly complex in structure and variety. Even when fragmentation and access are solved for specific roles, some data types may be missing.
Here's where claims come in. They tackle the first barrier of fragmentation head-on. You see, a patient might have multiple healthcare providers, but they usually have just one payer at a given point in time (aside from edge cases like dual eligibles, veterans, or cash pay scenarios). Claims are the central hub that collects data from all these spokes, effectively centralizing information across a wide and disparate provider landscape.

Additionally, the established paths for claims processing ensure that parties with legitimate roles—such as payers (insurance companies), clearinghouses, auditors, certain healthcare providers, and patients —have the right to access this data, thereby tackling the access barrier. Increasingly, major regulators are pushing to enable a landscape of new API-driven approaches for each of these channels.
However, to most, claims data are an enigma wrapped in a mystery, surrounded by a conundrum, and the routes leading to that data form a labyrinth worthy of Greek mythology. Deidentified and identified data, obscure acronyms, varied formats, and varying purposes of use muddy the waters.
So, let’s enumerate the state of claims and, in doing so, clarify the weird world of healthcare’s financial data.
Types
When thinking about claims data, there are two basic patterns of use, driven by what problem a person is trying to solve:
Provision, navigation, and optimization of care for individuals: Claims data for specific patients allows various organizations involved in the chain of care (providers, plans, brokers, navigators, and more) to assist the patient by understanding their health in both financial and broad clinical terms. Identified data is needed/helpful when having substantial patient history is necessary for these tasks.
Identified claims data are needed here - while it’s possible to baseline costs or build optimal care pathways using deidentified data, it’s not possible to help someone without specifically tying the claims to their identity.
Analytics for insights about populations: Given that claims are a well-structured summary of key health data like medications, diagnoses, and procedures, it’s extremely common that organizations want bulk claims to understand trends and compare at a population level.
While identified data is hypothetically possible, it comes with burdensome HIPAA roles and consent considerations.
As a result, de-identified claims data sets are a common tool for this use case, as a much wider variety of organizations (pharma, financial analysts, public health researchers) can accomplish their business goals with considerably less friction and risk using that pathway.
In this piece, we’ll spend a bit more time on the identified paths to claims data, because:
Programs for identified claims access aren’t as well-known or detailed comprehensively, whereas the de-identified data sales space is extremely mature and has excellent write-ups like this one by Datavant
Programs for identified claims access are relatively new and changing thanks to regulation by the CMS

Definitions
When it comes to de-identification, HIPAA defines two major methods that are worth explaining:
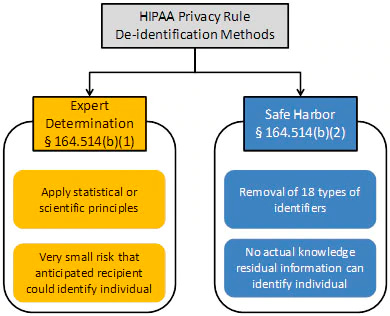
Safe Harbor, is deterministically and definitively de-identified. You are taking the dataset and going over it with a fine-toothed comb to erase any identifiable information, such as names, address info smaller than state, contact information, and patient/member/account IDs. With that information scrubbed, linking to other datasets is nearly impossible (aside from true tail-end edge cases, such as diseases rare enough to uniquely map to a single patient over a span of time). While usable for some high-level, generic analytics, this is not where the major de-identified data businesses play.
Expert determination is the crazy probabilistic cousin of Safe Harbor who plays it fast and loose. Using the power of <hand wave>math</hand wave>, a very smart statistician looks at a dataset to determine if the risk that anyone could use it alone or in combination with other reasonably available information, to identify an individual is small. This is magic of a very high order, with only a few wizards nationwide who are capable of this task. It is also probably more apt to call it pseudonymization - datasets using this path do not have all PHI removed, but instead have it altered, randomized, or generalized. For instance, instead of exact ages, age ranges might be used, or specific geographic locations might be broadened from a street address to a zip code or city. This is significantly more valuable than Safe Harbor for many buyers, in that understanding some of those basic demographics is useful! What age a patient was when they had a condition, what county they lived in, or their gender is all helpful in slicing and dicing the data to get to deeper insights and baselines.

On the identified claims side of things, given claims are Personal Health Information (PHI) under HIPAA, we see certain concepts commonly used across various data access programs that must be understood to ensure appropriate access.

Attribution: the method by which an organization (usually a payer) determines which healthcare provider is responsible for coordinating a patient’s care. This matters regarding claims data access because some data exchange is limited to attributed providers only.
In value-based care models, attribution gatekeeps any payment, so it’s well-defined, although the particular methods and algorithms for attribution vary. In fee-for-service, attribution is less critical, so the logic is thus less defined.
Prospective attribution assigns patients to providers at the beginning of a measurement period, while retrospective attribution does so after the period has ended, based on the care that was actually delivered.
Network status: Whether a healthcare provider is part of a payer's network. This is often a factor in claims data access in scenarios without strong attribution logic.
In-network providers have agreements with payers to provide care to their members at predetermined rates, while out-of-network providers do not have such agreements.
Purpose of use: the reason for accessing PHI, including claims data. HIPAA regulations stipulate that PHI should be used only for specific purposes such as treatment, payment, or healthcare operations.
Even when checking the boxes regarding attribution and in-network status, the reason for data use still matters. A provider pulling claims (or other) data to inform care (Treatment) does not have the same access rights if they were doing it for a marketing campaign or for analytics research (Operations).
With those ideas in mind, let’s dive in.
Going to be at ViVE 2024 in Los Angeles next week? The Flexpa team will be too. Reach out if interested to meet and chat all things claims data:
Data Exchange Methods

Deidentified
Deidentified data aggregators

Status: Active
Purpose: Help organizations who want to buy population-level deidentified claims (and other) data that the aggregator has compiled for the populations they care for
Scope: Any population a buyer might be interested in, so long as the seller allows it.
Data types: Datasets go well beyond claims, including clinical data. All data is deidentified
Technology: Data is usually provided in a user interface or flat file format
Who’s it for: Any party whose problem can be solved with population-level claims data without identity
In this model, the central party purchases and stores claims data from data sellers, normalizes and enriches it across datasets, and sells to any organizations that want to solve problems with deidentified claims data for their populations. Some get it from payers, some from clearing houses, and some from revenue cycle management systems. Often buyers can provide their keys and additional data to get added in with the data for use cases such as benchmarking. For instance, a risk-bearing entity can provide their patient roster and get the "de-ided" records that they cover flagged so they can do comparative analysis.
This is a variation of the “dump it all in a big database” method of data sharing. There are many groups offering this model:
It’s very opaque in nature - very few of these groups give visibility in which proprietary datasets they’ve aggregated, and many are interconnected/customers of one another. According to some I talked to, there’s good reason for that secrecy and murkiness - given that de-identification is not some ironclad, impenetrable programmatic measure, but instead trusting that contractual levers and bindings will be respected, re-identification is rampant across the industry. With that in mind, the originators don't want PR blowback if someone downstream gets called out for doing something (like linking re-identified data for targeted marketing). As one expert commented when discussing this particular type of entity:
“Dealing with this particular vertical industry is the closest I've ever felt to waking up next to a horse head.”
Most aggregators have pretty strict contracts in place about not revealing where their data is coming from (it can often be deduced, though), and then, in turn, buyers of that aggregated data have contracts that prevent them from revealing who the aggregator is. Similarly, the quality and guarantees of the data can vary wildly across aggregators and even use cases, as some data sources will block their data from being re-sold based on the industry of the end customer. For example, a payer may allow an aggregator to license their data for life sciences but block it to other payers.

Deidentified tokenization networks

Status: Active
Purpose: Help organizations who want to buy claims (and other) data find the sellers that have records for their patients.
Scope: Any population a buyer might be interested in
Data types: Datasets go well beyond claims, but core functionality is facilitating patient matching across data holders and data purchasers
Technology: Data is usually provided in flat file format
Who’s it for: Any party whose problem can be solved with population-level claims data without identity
In this model, the central party does not actually have claims data. These networks mediate identity in a decentralized, privacy-safe way (tokenization) between data holders (like payers and providers) and data purchasers (health analytics, government, academic researchers, employers, digital health companies, and more). By staying away from a “dump all your claims in this database” model and focusing on deidentified record location services, these data networks offer an alternative solution to aggregators that gives data holders more control. The biggest player here is Datavant.

If data aggregators were metaphorically mail-order bride services, directly controlling supply to help interested parties identify a suitable match, deidentified data networks are Tinder, having no direct supply but instead matching based on either side submitting just enough information to identify good pairs without oversharing.
All-Payer Claims Databases
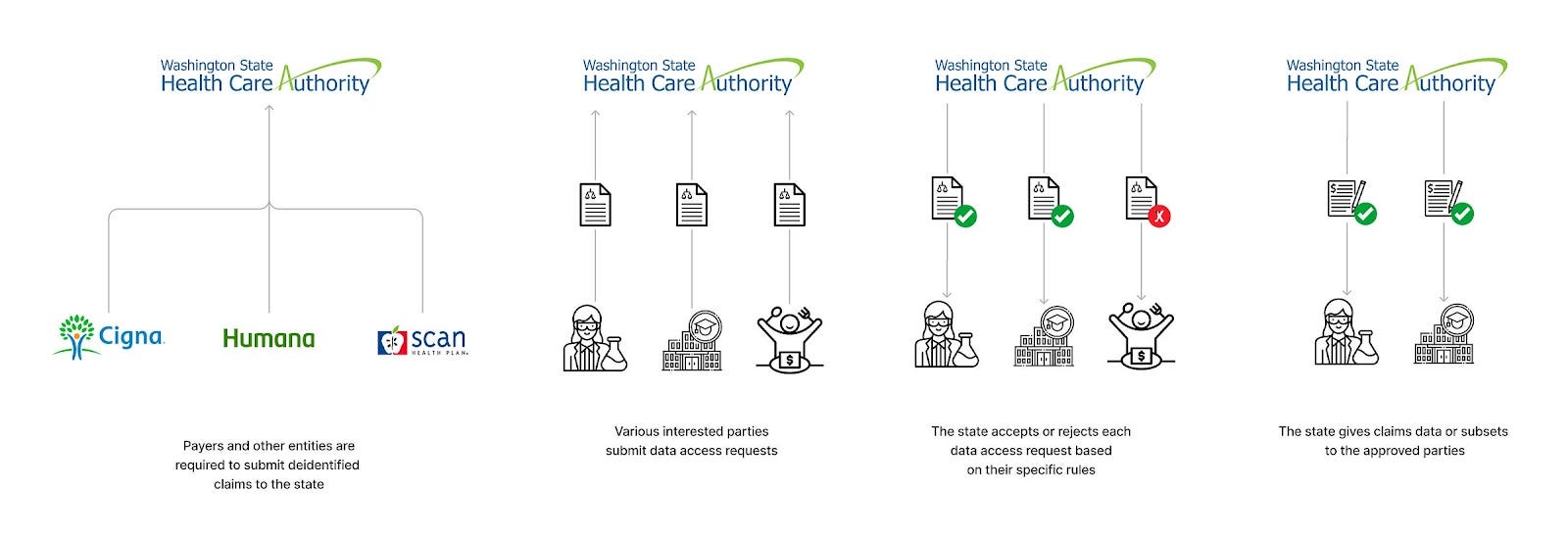
Status: Active (in some states)
Purpose: APCDs aim to collect health claims data from a variety of payers to provide a comprehensive view of healthcare costs and utilization within a specific geographic area. This data is typically used for healthcare policy decision-making, research, and to improve healthcare cost transparency.
Scope: Populations specific to a state, excluding self-funded, workers comp, Tricare & VA, and Federal Employees plans
Data types: APCDs generally create Public Use Files that summarize all aggregated claims data they have (which may exclude some plan types, such as federal or self-funded). They may also create more specific, “limited use” claims files for certain use cases that may include some basic PHI.
Technology: The data in APCDs is generally a flat file in format. There is a push for a common data layout (APCD-CDL)
Who’s it for: APCDs are valuable for state governments, policymakers, researchers, and public health officials. Beyond that, variable by state - some have broader data use provisions and pathways that sometimes allow commercial use.
APCDs are a very specific type of deidentified data aggregator. Think of APCDs as the health information exchanges of deidentified claims data - they’re state-mandated databases to collate claims from payers that operate in the state. The breadth of plan types included in the mandate varies (some states, such as Virginia, have had pushback on self-funded plans, for instance) as do the data use request processes. Simply put, the datasets are often incomplete. As a result, it’s really hard to generalize and requires a state-by-state deep dive to do the space justice.

As mentioned, some states include basic identifiable data for limited use cases.
While APCDs offer an interesting and cool alternative to the high price tags of data aggregators, in reality, the restrictions of the varied data use agreements and overall lack of standard process, format, and policy often make all-payer claims databases difficult to use for those that qualify and a non-option for various commercial use cases.
In addition to state APCDs, local and federal governments often operate more direct de-identified claims exchanges, such as the CMS Qualified Entity program or state Medicaid databases.
Read more about APCDs here.
Identified
CCLF (Claim and Claim Line Feed) files

Status: Active
Purpose: Give Accountable Care Organizations (ACOs) the claims data for their beneficiaries on a monthly basis for analytics, reporting, and auditing purposes.
Scope: CMS-attributed population
Functionality: Medicare Parts A, B, and D claims
Technology: Data is usually provided in delimited text file formats. The data files that ACOs receive monthly consist of five Part A files, three Part B files, one Part D file, one beneficiary demographics file, one beneficiary MBI cross-reference file, and one summary statistics file
Who’s it for: Medicare Accountable Care Organizations
Thoughts: This is the OG standardized format for claims data exchange. History on it is sparse, but as far as I can tell, it started sometime around 2015, based on a reverse-sorted Google search. It’s a gross flat-file format, but it’s well-defined and delivered monthly, which is better than the Wild West of payer-to-provider data exchange outside of CMS. It’s also not bound by purpose of use like Data at the Point of Care, but it’s strictly only for Accountable Care Organizations.
The nice thing about Accountable Care Organizations is that attribution is very clean and decided up front (prospective attribution), which avoids the need for attestation by a provider of attribution/a treatment relationship.

Read more: CMS Information Packet
CMS BCDA (Beneficiary Claims Data API)

Status: Active
Purpose: Aids Accountable Care Organizations (ACOs) participating in the ACO Realizing Equity, Access, and Community Health (ACO REACH) Model in accessing and sharing Medicare claims data.
Scope: CMS-attributed population
Data types: Medicare Parts A, B, and D claims
Technology: Leverages bulk FHIR API for efficient data retrieval.
Who’s it for: ACOs and other healthcare organizations that require bulk access to Medicare data for analytics and better care coordination but don’t like flat files.
Thoughts: BCDA is the replacement for CCLF. It’s nearly identical, except:
It’s bulk FHIR in format, rather than a custom (well-defined) flat file format.
BCDA receives claims data on a weekly cadence, while Claim and Claim Line Feed (CCLF) files receive them monthly
BCDA recently announced support for partially adjudicated claims, which seems like an improvement over CCLF.
Given that ACOs, like most value-based care programs, have a clean attribution process, it doesn’t require attestation by the provider, as the CMS figures that out before serving up any one patient’s data. BCDA is also not just for treatment purpose of use - ACOs can use the data for broader purposes of use.
So the math is simple here: if you’re an ACO, upgrading from CCLF to BCDA benefits you with less laggy, higher fidelity data, with the cost of needing to parse and understand FHIR.
Read more: CMS BCDA Website
CMS AB2D (Medicare Claims Data to Prescription Drug Plan Sponsors) API

Status: Active
Purpose: Allows Prescription Drug Sponsors to access claims data for optimizing therapeutic outcomes through improved medication use, improving care coordination so as to prevent adverse healthcare outcomes, health care operations, and fraud and abuse detection or compliance activities.
Scope: CMS-attributed populations
Data types: Medicare Parts A, B, and D claims
Technology: Leverages bulk FHIR API for efficient data retrieval.
Thoughts: This is really quite similar to BCDA but tailored to prescription drug sponsors in terms of onboarding.
Congress passed a law (Bipartisan Budget Act of 2018, section 50354) in 2018 that required CMS to do this, which is rare and wild in and of itself. Direct legislative mandate is really hard to come by - most of the APIs here are either CMS just winging it (DPC, BCDA, Blue Button) to make things better for Medicare patients or taking regulatory prerogative into their own hands with indirect legislative mandates (CMS-9115). Note to any Congresspeople reading this - consider yourself notified that directly enabling and empowering the CMS with authority for higher leverage health API initiatives via legislation would be dope.
Beyond who it’s for and Congress’ weird interest in it, there's not a ton to say here, given how similar it is to BCDA. I found their documentation to be the most confusing of the four CMS programs by a mile - API information was spread across four pages and a GitHub repository. The data dictionary is rad, though.
Read more: AB2D Documentation
CMS DPC (Data at the Point of Care) APIs

Status: On hold (they have paused the pilot and new organization onboarding)
Purpose: Enhances healthcare delivery by providing fee-for-service clinicians with Medicare claims data at the point of care.
Scope: Provider-attributed populations (if they’ve submitted a claim for that patient within the last 18 months)
Data types: Medicare Parts A, B, and D claims
Technology: Uses FHIR API to integrate data directly into EHR and other provider-facing systems.
Who’s it for: Fee-for-service healthcare providers, specifically clinicians, with a treatment purpose of use
Thoughts: DPC is pretty neat on paper, offering population-level access to claims data for Medicare FFS providers. Although traditional Medicare doesn’t have the same attribution logic as ACO Reach, the provider can assert attribution (rather than have the CMS decide who is attributed), which is equivalent to claiming an active treatment relationship. This means a broad group of providers involved in the care of patients hypothetically could access claims data for those populations.
However, there are caveats that limit it a bit:
The onboarding of new organizations and vendors has been fully paused since last summer. Details are scarce, but they’ve struggled to properly verify organizations as part of the onboarding process, which is important given only providers (and their vendors) should be able to use this program.
CMS “checks” that the validity of the provider/patient relationship is active by only returning data for patients who have a claim associated with the requesting provider organization or practitioner in the last 18 months. This makes it useless for “first touch” use cases, such as registration and onboarding. It also means that groups can’t pull for patients they haven’t or won’t see (a feature, not a bug).
Read more: CMS DPC Website
CMS Blue Button 2.0 APIs

Status: Active
Purpose: Empowers Medicare beneficiaries with direct access to their health data.
Scope: Individually consented patient-by-patient
Data types: Medicare Parts A, B, and D claims
Technology: Utilizes OAuth 2.0 and FHIR (Fast Healthcare Interoperability Resources) standards for secure data access.
Users: Medicare beneficiaries and developers building applications for this audience.
Thoughts: Individuals in Medicare can authorize the sharing of their data to the applications of their choice. It’s as simple as that. There’s a friction there that isn’t present in DPC, BCDA, or AB2D, in that the member needs to remember their username and password and have motivation to share their data. However, it’s conversely quite powerful in that it avoids the limitations of those other programs:
It can be used by applications of a variety of use cases beyond just providers, ACOs, or plan sponsors
It can be used for purposes of use beyond just treatment
It’s not bound by the attribution logic of the CMS or gated by the submission of a claim, allowing quicker access to claims data
It’s important (perhaps pedantically so) to mention that these are the 2.0 APIs, built using FHIR. The original version was a branch of the Veteran Affairs’ Blue Button initiative, which imagined a world where patient access was as simple as clicking a blue button and receiving a file (first an ASCII format, then a standardized CDA format).
Read more: CMS Blue Button Documentation
Patient Access APIs (CMS-9115)
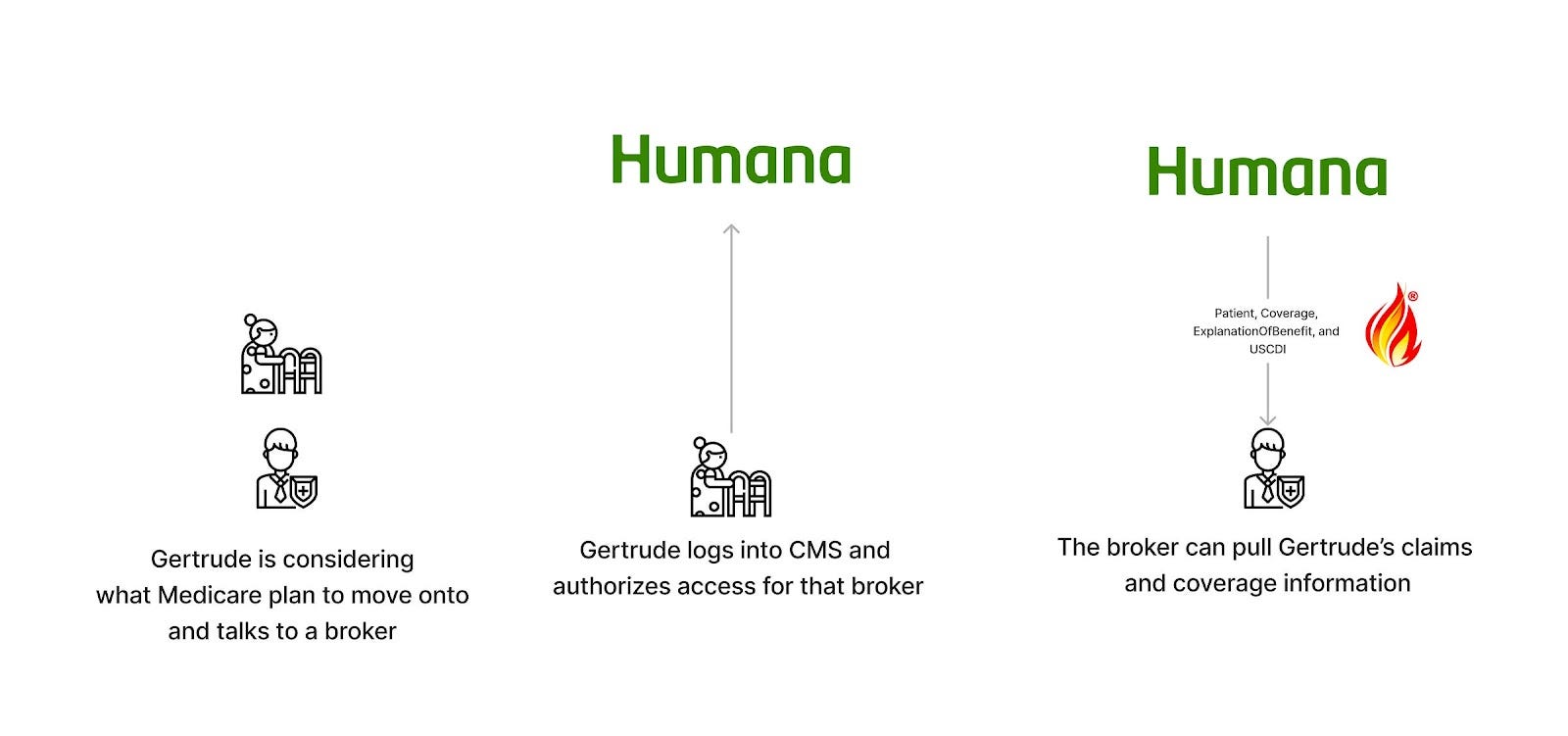
Status: Active
Purpose: Enables Medicare Advantage, Medicaid, CHIP, and ACA patients to access their health data, claims, and encounter information through third-party applications.
Scope: Individually consented patient-by-patient
Data types: Claims and clinical data for MA, Medicaid, CHIP, and ACA plans
Technology: Utilizes FHIR and OAuth 2.0, similar to Blue Button.
Who’s it for: Patients on public plans covered by private payers and app developers targeting this audience.
Thoughts: In the wake of the Cures Act giving the ONC authority over providers to iterate on the EHR certification program with FHIR APIs, the CMS wanted to get in on the action. Lacking a direct mandate or authority from the Cures Act, they wrangled together authority derived from previous legislation (Social Security Act and the Affordable Care Act, primarily) and made the CMS Patient Access and Interoperability Rule to compel payers and state Medicaid agencies to expose Patient Access APIs (modeled on the Blue Button 2.0 APIs they had created) for Medicare Advantage, Medicaid, CHIP, and ACA plans.
These APIs actually go a bit broader than Blue Button, though. Whereas the CMS program only includes the core claims data (Patient, Coverage, and ExplanationOfBenefit resources), the APIs from the CMS mandate require that payers make patients’ clinical data available (to the extent that they have that data) as defined by USCDI.
These APIs are also subject to the same limitations and benefits as Blue Button. There’s the friction of a user authorizing the exchange, but also the much broader use cases it can be used for, allowing non-providers to access data and enabling timely retrieval during first touch moments.
Flexpa deals specifically with these APIs today, connecting to all available plans and normalizing the incredible variation in authorization, structure, and developer experience. If that’s interesting to you, we’d love to talk: Talk to the Flexpa team
Read more: CMS-9115 Info Page
Provider Access APIs (CMS-0057 )

Status: Future
Purpose: Enhances healthcare delivery by providing in-network clinicians with Medicare Advantage, Medicaid, CHIP, and ACA claims data at the point of care.
Scope: Payer-attributed populations
Data types: Claims (no financials) and clinical data for MA, Medicaid, CHIP, and ACA plans
Technology: Uses bulk FHIR API to integrate data directly into EHR and other provider-facing systems from payers
Who’s it for: In-network healthcare providers, specifically clinicians, looking to augment their care delivery
Thoughts: The CMS finalized its latest rule, CMS-0057, in January, which mandated a number of new APIs for payers to expose. The Provider Access API takes the rough blueprint that the CMS’ own APIs for provider access (BCDA, DPC, AB2D) started and expands it to all public plans run by private payers under CMS authority.
They made some interesting choices in the design here:
Network status - The rule only requires these APIs for in-network providers.
Attribution - They opted for more of a BCDA approach, allowing payers to decide attribution, rather than the DPC provider-oriented approach or industry standard implementation guides like Da Vinci Member Attribution. Beyond that, they were painfully handwavy about attribution logic, simply saying that each payer must have such logic and must list it publicly on a website.
Opt-out patient consent - The rule dictated that this particular API defaults patients into sharing this data with their attributed, in-network providers but also mandated that payers give them a way to prevent that sharing if they choose.
Available data - The dataset available via these APIs sits somewhere between CMS’ own programs (claims only) and the CMS Patient Access APIs (full claims and clinical data), in that payers are required to share adjudicated claims and encounter data, clinical USCDI data, and prior authorization information, but the claims data does not include provider remittances and patient cost-sharing information (i.e. how much the provider was paid and the patient’s liability). With that in mind, the data is more pseudo-claims, removing financial information and leaving just the clinical aspects.
As a result, this group of APIs will be interesting to watch as we close in on the mandated date (January 1st, 2027) to see if future CMS guidance and industry collaboration lead to relatively uniform implementations (unlikely) or if this will be a wild west of attribution and API design (highly probable).
As the market-leading platform for connecting claims data, Flexpa’s provider customers are already utilizing claims data via the CMS-9115 APIs. With the finalization of the new CMS rule, we have been actively exploring payers’ implementations of the Provider Access API to augment our existing approach. We’d love to talk to any provider groups starting to think about their connectivity here: Talk to the Flexpa team
Read more: CMS-0057 Info Page
Payer-to-Payer APIs (CMS-0057)
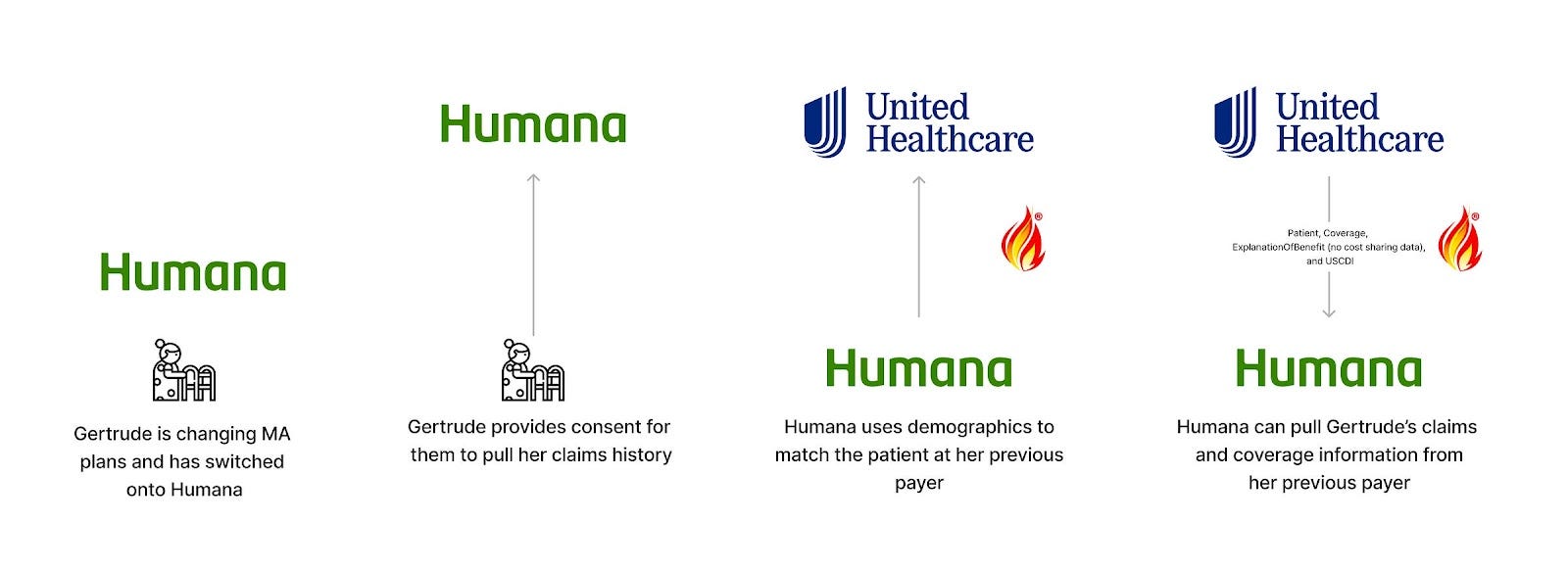
Status: Future
Purpose: Enables data to follow individual patients across disparate health plans, ensuring that no information is lost, helping payers onboard and prioritize services for new members.
Scope: All existing members at the time of compliance date (Jan 1, 2027) and any newly onboarding members that opt-in
Functionality: Facilitates access to Medicare Advantage, Medicaid, CHIP and ACA claims (excluding provider remittances and cost-sharing data) and clinical data from a member’s prior payer
Technology: Uses bulk FHIR APIs to facilitate claims data transfer from an old payer to a new payer
Who’s it for: Payers onboarding new members or payers with members enrolled in multiple plans simultaneously
Thoughts: As mentioned, CMS-0057 outlines many APIs. Another notable one for claims data access is the payer-to-payer API, which is designed to allow a member to “carry forward” their prior history from payers as they change insurances.
Some fun nuances and carve-outs here as well:
Opt-in patient consent - In contrast to the Provider Access API, the CMS decided on an opt-in process for Payer-to-Payer, where existing members would be prompted by the compliance date, and new members would be presented with the choice during enrollment. This seems to be intended to prevent payers from broadly abusing the connectivity to pull data, perhaps showing CMS’ hand a little on how they view payers and providers. This is also fascinating in that the consent is on the “requesting” side and not the “responding” side, necessitating true trust that the patient is active and opted-in by any payer requesting data.
Coverage gaps - There’s a big hole in the vision of an ongoing, pull-forward member history here: Payers and plans not subject to the rule. Given the CMS’ authority over only a subset of plans, the history is somewhat limited when members move from non-regulated plans. For instance, Medicaid patients often bounce between that plan type, traditional employer-based insurance, and ACA, leading to gaps in history for those commercial plans (or even some ACA plans on state-based exchanges).
Available data - Similar to the Provider Access API, while payers must share adjudicated claims and encounter data, clinical USCDI data, and prior authorization information, the claims data does not include provider remittances and patient cost-sharing information (i.e. how much the provider was paid and the patient’s liability).
Technical standards - The CMS rule leaves a lot of leeway in terms of implementation, requiring FHIR bulk data but then recommending both CARIN Blue Button and DaVinci. It’s not clear on the exact interplay the CMS intends here. A significant amount of implementation variance should be expected, given the overall lack of specificity,
The jury is also still out on this one, given the January 2027 compliance date, but it’s worth tracking if you’re an affected payer, obviously.
As with the provider access APIs, Flexpa already has been helping payers jumpstart onboarding of new members using the existing CMS-9115 Patient Access APIs. We also have been cataloguing all available payer-to-payer implementations to ensure we continue to offer the easiest, deepest, and most comprehensive experience to our payer customers and their members. If you’re an innovative payer starting to turn your investment into CMS mandates from compliance burden into real and meaningful workflow improvements, we’d love to talk: Talk to the Flexpa team
Direct payer relationship

Status: Active (if you have a payer relationship)
Purpose: Provide claims and other data to close provider and employer partners in order to manage spend and prioritize care
Scope: Attributed populations (for providers) / employees (for employers)
Data types: Attribution rosters, coverage information, and claims. Occasionally other data, such as encounters.
Technology: Custom flat files over SFTP all the way down
Who’s it for: Facilitates access to claims data for providers or employers (or their software partners)
Thoughts: There are situations where organizations grow really, really close with insurers.
When you’re a provider doing value-based care, you get close with your payer partners by necessity. It is in their best interest for you to succeed, reducing their costs and increasing their margin (generally in terms of what the CMS pays them). Providing data like attribution rosters and claims helps you provide care more efficiently.
With employers, you are a customer of the payer. If you are large enough, you have the weight to influence the relationship to get what you want. That can include claims data for your employees so that you can analyze healthcare spending patterns, identify opportunities for cost savings, and tailor wellness programs to address specific health needs within your workforce. This data becomes instrumental in negotiating better rates, designing employee benefits that genuinely improve health outcomes, and implementing preventative measures that can reduce the need for expensive treatments or hospitalizations.
When you have those sorts of close relationships (or other varieties of unique B2B partnerships), payers will grant you access to claims. It will not be FHIR. It may be X12. But most of the time, it will be flat files.
People love to dunk on fax, but flat files might be the true villain in healthcare and beyond. CSVs and other similar formats are so damn easy to generate that they are more commonplace than any other format. However, they are custom to each data provider and, therefore, as variable as the wind, with repeated redundant work with each new partner. Beyond that, they are so brittle and breakable, with new columns arriving catastrophically by an inadvertent comma.
Thus, the simplicity of flat files is a double-edged sword, slicing through the Gordian knot of creation of data exchange with one hand, while sowing seeds of chaos of receiving with the other. Providers and employers bear the brunt of this and need an extremely high level of sophistication to deal with this at scale, maintaining the ingestion pipeline and implementing rigorous quality assurance processes on files. On the other side, smaller payers may lack the resources to implement this sort of exchange at all. Riddled with these inconsistencies and plagued by lagging attribution on the scale of months or quarters, this sort of exchange is the best available option by being the only available option.
Direct provider relationship - EHR

Status: Active (if you have a provider relationship with a good EHR)
Purpose: To give financially oriented business associate applications the data they need to solve problems
Scope: Patients specific to a partner provider organization
Data types: Live feed of claims and remittances, sometimes claims history, specific to a partner provider organization to partner business associate applications.
Technology: X12 837 and 835 formats, sometimes custom flat files
Who’s it for: Business associate applications integrating with a health system or clinic that need that institution’s claims
Thoughts: If you’re building something for providers, you sit in the orbit of the EHR and practice management system. Integration is universally hard, given the sheer variety of formats, standards, and methods you need to consider and use.
Little known fact, though - there’s a hard mode if you’re looking for it. Financial data is a level up in difficulty, exacerbating all the issues you see with traditional integration. This is because:
The average health system or clinic may have dozens or hundreds of ancillary applications for clinical functions, which builds an aggregate customer demand for data exchange mechanisms. This is not true for financial applications, where a given organization generally only has one or two ancillary systems.
EHRs and practice management systems often want to own this function
Financial data is viewed as Proprietary™ by the healthcare system.
Regulation has not promoted financial interfaces and APIs aside from the basic “can you send and receive X12 with a clearinghouse”.

The end result is that EHRs lack the same level of sanctioned interfaces for financial concepts as they have for clinical ones - they simply haven’t built them. They generally can ingest charges from ancillary systems but have no way of exporting them. They have extremely limited interfaces for patient responsibility or payments. Most importantly to this article, they don’t always have the ability to send X12 837 claims to a second destination or echo back out X12 835 remittances after receiving them.
Beyond that, if an app needs a full claims history for a patient at that provider organization, the X12 duplication method doesn’t provide that. Few EHRs or PM systems have a clear path for this historically - apps have to hope for a proprietary API or a custom flat file to get what they need.
Thus, apps needing claims data are in a tough spot and woefully underserved today. Hopefully, future regulation or customer demand will lead to more EHRs exposing financial FHIR resources, as Epic has done with ExplanationOfBenefit or Cerner with FinancialTransaction.
Direct provider relationship - clearinghouse

Status: Active (if you have a provider relationship with a good clearinghouse)
Purpose: To give financially oriented business associate applications or provider organizations the data they need to solve problems
Scope: Patients specific to a partner provider organization Live feed of claims and remittances, sometimes claims history, specific to a partner provider organization
Data types: Live feed of claims and remittances, sometimes claims history, specific to a partner provider organization to partner business associate applications.
Technology: X12 837 and 835 formats, portal scraping
Who’s it for: Provider organizations or business associate applications integrating with a health system or clinic
Thoughts: If you’re not familiar with clearinghouses, they are the OG data middlemen. With the advent of financial data exchange in healthcare, the many (payers)-to-very-many (providers) problem drove an immediate need for “connect once, integrate with all” for easier claims payments. Thus, healthcare witnessed the rise of these archaic behemoths, creating a web of connectivity that means a provider can submit a claim to any one clearinghouse without tons of point-to-point connections. There are a few big ones (Availity, Trizetto, Waystar, Change, Claim.MD) and many much smaller ones. I tried to find a comprehensive list but failed, aside from Clearinghouses.org, a truly glorious Wordpress with the aesthetic of a late 2000 scam site.
Given that almost all providers have a relationship with a clearinghouse (and, in many cases, several clearinghouses) to send and receive claims, these entities offer the hypothetical possibility of solving some claims-related problems:
For business associates: in the event that the EHR-oriented approach detailed above is not viable, the clearinghouse may be able to send a duplicate live feed
For providers and their business associates: these clearinghouses may store all claims that pass through them, offering the ability to see a fuller picture of a patient’s claims history
The main issue here is that this is a variable experience. Some clearinghouses may be quite advanced, offering easy ability for apps to receive claims for all their provider partners. Others may have limited options, such as a web app to view claims.
Wrap-up
Look, we get it. That was an absolute barrage of acronyms, actors, file formats, organizations, and entities. And really, this is just the tip of the iceberg - each of the different pathways to claims data has a ton of hidden nuance and context-specific implementation variation that make each deserving of its own 5000-word article. With some high-level understanding of the landscape, though, we hope you’re equipped to begin your claims data journey and solve some of healthcare’s biggest problems.
And if you’re still feeling uneasy about it all and want to dive deeper, you can always talk to the Flexpa team.
A huge shout-out to all who provided feedback and edits on this article (Andrew Rosenthal, Angela Liu, Brian Dailey, Colin Keeler, Garrett Rhodes, Michael Stratton).
We did not call up the Quad City DJs, nor are we friends with them, but we wish we were.
this has instantly become a classic
This is just an incredible resource. Thanks for writing this up!